Quickly on Site Reliability Engineering (SRE)
Site Reliability Engineering (SRE) is a set of practices that applies software engineering principles to IT operations. It aims to improve system reliability, scalability, and efficiency while minimizing downtime. SRE teams focus on automating manual tasks, reducing operational toil, and maintaining a balance between system reliability and the velocity of new feature releases.
SRE’s ultimate goal is to build and maintain resilient systems that can handle failures gracefully, ensuring high availability and performance.
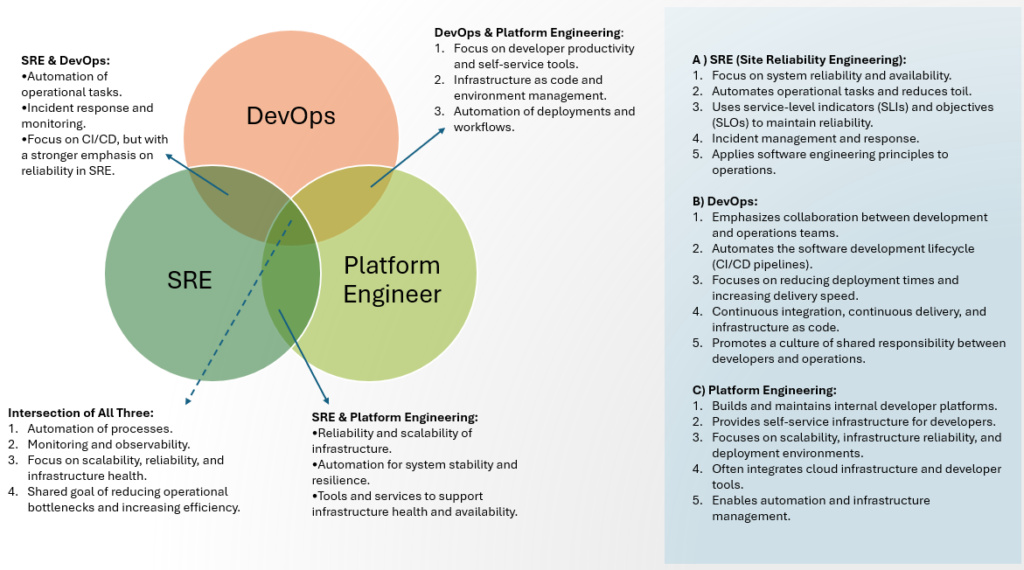
Let’s visualize using the Venn diagram, how SRE, DevOps, and Platform Engineer are placed
Steps to Implement Reliability Engineering
To successfully implement reliability engineering within your organization, it’s essential to follow a structured approach that combines strategy, tools, and culture.
1. Establish a Reliability Mindset Across Teams
Reliability engineering isn’t just the responsibility of the SRE team; it’s a cultural shift that needs to be embraced by the entire organization. Everyone, from development teams to product owners, should prioritize system reliability as a key objective.
Steps to Implement:
- Conduct training sessions on the importance of reliability.
- Foster collaboration between SREs, developers, and operations teams.
- Encourage teams to set and monitor SLOs for their services.
2. Invest in Observability and Monitoring Tools
High levels of observability are critical for effective reliability engineering. Choose and implement tools that allow teams to monitor logs, metrics, and traces to gain insights into system behavior and performance.
Steps to Implement:
- Implement centralized logging and monitoring platforms (e.g., Prometheus, Grafana, ELK Stack).
- Create dashboards for key SLOs and SLIs.
- Set up alerts for any deviations from normal behavior.
3. Design for Failure and Redundancy
Assume that failures will happen and design systems to be fault-tolerant. Build in redundancy to ensure that single points of failure do not bring down the entire system.
Steps to Implement:
- Introduce redundancy at every layer (e.g., databases, network infrastructure).
- Use auto-scaling and load-balancing mechanisms to ensure availability.
- Apply distributed systems principles, such as partitioning and replication, for critical services.
4. Start Small with Chaos Engineering
Begin by introducing Chaos Engineering in non-production or pre-production environments to gain insights without affecting customer-facing systems. Gradually increase the complexity and introduce chaos into production environments once you’re confident in the system’s resilience.
Steps to Implement:
- Set up Chaos Engineering tools (e.g., Gremlin, Chaos Monkey).
- Define failure scenarios (e.g., network latency, service crashes).
- Analyze system behavior and implement improvements based on findings.
5. Create and Enforce SLAs, SLOs, and SLIs
Without clear objectives, it’s difficult to measure system reliability. Define and enforce SLOs, SLAs, and SLIs to ensure that systems meet expected reliability targets.
Steps to Implement:
- Define meaningful SLOs for each service based on user requirements.
- Set SLAs with customers to formalize reliability commitments.
- Continuously track SLIs to ensure adherence to defined objectives.
6. Prioritize Incident Response and Postmortems
Reliable systems depend on fast, effective incident response and continuous learning. Implement clear incident response processes and use postmortems to document learnings and improve systems.
Steps to Implement:
- Set up an on-call rotation for fast incident response.
- Use incident management tools (e.g., PagerDuty, OpsGenie).
- Conduct blameless postmortems and track action items to resolve root causes.
Final thoughts
In an era where downtime can result in significant business impact, reliability engineering has become essential. By focusing on key areas like observability, error budgets, chaos engineering, and automation, organizations can minimize downtime and provide a seamless user experience