Building an end-to-end machine learning (ML) pipeline requires addressing various stages, from data acquisition and preprocessing to model management and deployment. The below picture is an organized framework using the components you provided, detailing each stage of the ML pipeline.
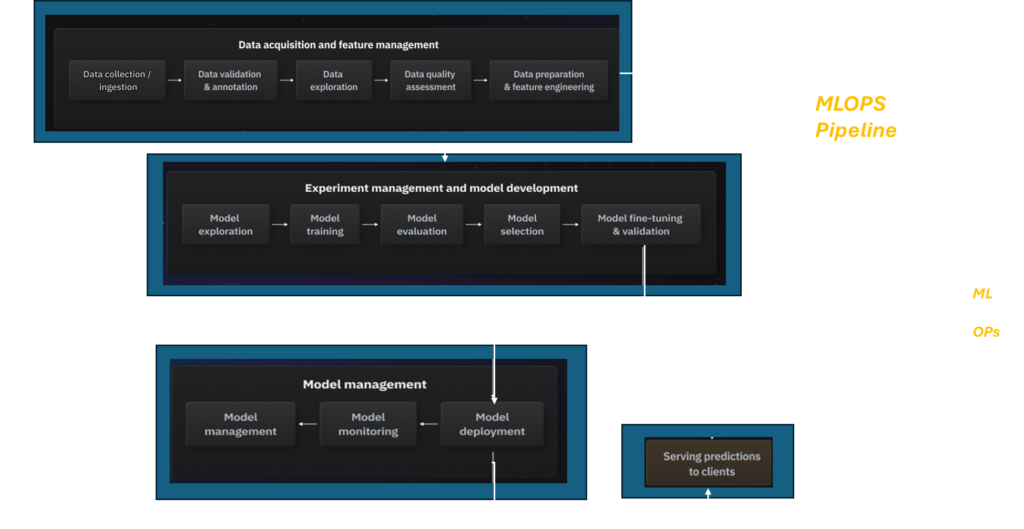
Data Acquisition and Feature Management
| Stage | Objective | Steps | Tools |
|---|---|---|---|
| Data Collection / Ingestion | Collect raw data from various sources | -> Identify data sources -> Set up continuous/batch ingestion | Apache Kafka, AWS S3, Azure Data Factory |
| Data Validation & Annotation | Ensure data correctness, completeness, and consistency | -> Validate data formats, types -> Handle missing values -> Annotate or label data | Great Expectations, Pandas, Labelbox |
| Data Exploration | Understand patterns, distributions, and potential correlations | -> Statistical summaries -> Visualizations -> Handle outliers and imbalances | Pandas, Seaborn, Matplotlib |
| Data Quality Assessment | Evaluate the integrity and quality of data | -> Check completeness, accuracy -> Assess data distribution | Pandas Profiling, DataRobot, Trifacta |
| Data Preparation & Feature Engineering | Transform data into features suitable for model training | -> Normalize/standardize data -> Feature extraction -> Feature selection | Scikit-learn, Featuretools, PySpark |
Model Development and Training
| Stage | Objective | Key Steps | Tools |
|---|---|---|---|
| Model Exploration | Explore algorithms and approaches | -> Baseline models for benchmarks -> Explore model types (linear models, neural networks) | Scikit-learn, TensorFlow, XGBoost |
| Model Training | Train machine learning models | -> Split data into training/validation sets -> Set hyperparameters -> Train models | Scikit-learn, TensorFlow, PyTorch |
| Model Evaluation | Assess model performance | -> Evaluate with metrics (accuracy, precision, recall) -> Cross-validation | Scikit-learn, MLflow, Keras |
| Model Selection | Select the best-performing model | -> Compare performance based on metrics -> Hyperparameter optimization | Scikit-learn, Hyperopt, Optuna |
| Model Fine-tuning & Validation | Fine-tune the model for better performance | -> Adjust hyperparameters -> Additional validation | Hyperopt, Keras Tuner, MLflow |
Model Management
| Stage | Objective | Key Steps | Tools |
|---|---|---|---|
| Model Management | Organize and version control models | -> Version models with metadata -> Track model iterations | MLflow, DVC, Weights & Biases |
| Model Monitoring | Monitor model performance in production | -> Set up monitoring for performance -> Detect model drift and performance degradation | Prometheus, Grafana, Evidently AI |
| Model Deployment | Deploy models into production | -> Deploy models as APIs -> Automate CI/CD pipelines | Docker, Kubernetes, AWS SageMaker |
This pipeline can be orchestrated using platforms like Kubeflow, MLflow, or TFX for better scalability and automation across all stages.